A look back at the development of ASReview and what lies ahead
From a coffee break conversation to a global open-source ecosystem: the complete story of how ASReview came to exist. Discover why we believe AI should be a ‘Super Assistant’ rather than a replacement of humans, and how we secured a future where the software remains free, open, and accessible to all.

The Role of AI: A Super Assistant
Medical guidelines, dosage recommendations, food safety standards, meta-analyses, and policy reports all require a systematic overview of the current state of affairs. While the process involves many steps (searching, quality assessment, data extraction, and interpretation), the screening phase is the most time-consuming and tedious. Here, experts must sift through hundreds or even thousands of results to identify the few that are actually relevant. It is an enormous effort, yet critically important, as the results often directly affect individuals’ daily lives.
Simply replacing the screening effort with AI is possible to some extent, though current results remain sub-optimal. However, even if full automation were achievable, it would still be undesirable for some tasks. Yes, AI excels at processing enormous amounts of data to identify patterns and correlations. Also, it can summarize texts, flag inconsistencies across thousands of documents in seconds, and organize unstructured text to create order from chaos within datasets vastly too large for manual processing. However, there are decisions where we strictly want human experts to bear the ultimate weight of the consequences. especially for decisions that impact human life, where we must ensure there is a ‘traceable human signature’ on the outcome.
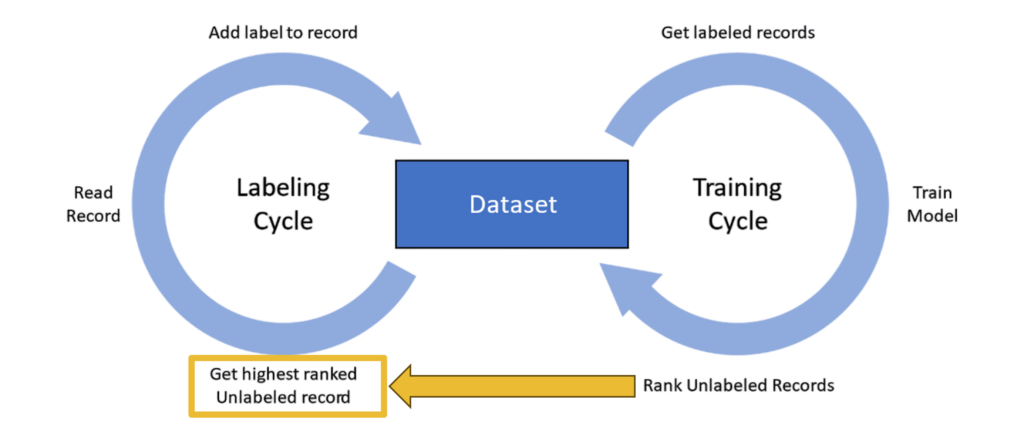
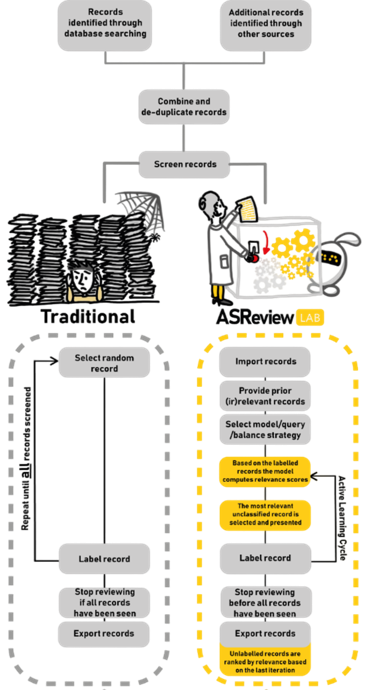
Therefore, to address the challenge of selecting relevant documents, I believe AI should serve as a ‘Super Assistant’, acting as a recommendation system that helps experts navigate enormous document sets, while the human remains the ‘Oracle’, the final authority on whether a document is included in the final product. This workflow is known as Human-in-the-Loop, a specific application of Active Learning often referred to as ‘screening prioritization’. Its value is officially recognized in methodological standards for systematic reviewing, including the updated PRISMA guidelines.
Small Models, Big Impact
Notably, the screening prioritization approach was effective long before the recent generative AI revolution popularized by OpenAI. Just like the models from OpenAI and similar providers, Active Learning frameworks rely on language models, often pre-trained on textual data. The critical difference, however, lies in scale, both in terms of training data and model size. While the current trend with Large Language Models (LLMs) is to maximize data ingestion, we favor small models. We prioritize the smallest effective model for the task at hand, preferably one efficient enough to run locally on a standard laptop.
Moreover, I personally prefer transparent, reproducible, and open-source models. For me, transparency is not just a preference; it is a necessity for scientific integrity. Without it, we cannot verify how decisions were influenced, detect potential biases in the algorithm, or ensure that a study can be replicated in the future, even if proprietary models have changed or vanished, keeping the process trustworthy and verifiable.
From Boredom to Breakthrough: The Origin Story
~~ Rewind to early 2017 ~~
I was screening through thousands of abstracts for a review on PTSD trajectories following traumatic events. At the time, I was unaware of the technical possibilities; I just knew I was incredibly bored. When Daniel Oberski walked by my office, I vented my frustration about the inefficiency of the process, and we immediately sat down to sketch a solution: a pipeline that could support a screener using Active Learning. We submitted this rough idea to a ‘high-risk, high-gain’ grant call at our university’s ITS department.
To our delight, we were awarded the funding. Jonathan de Bruin, open-software expert, and his team began building a simulation pipeline designed to mimic the screening process. This allowed us to benchmark classical ‘random’ screening against our Active Learning approach. After about a year, the results were undeniable; the efficiency gains were massive.
In those early days, our tool was powerful, but it wasn’t exactly pretty. It operated through a ‘Command Line Interface’, which basically means typing instructions into a black screen with white text. It was a tool built by geeks, for geeks.

Despite the technical look, we knew we had something special. We published the code on GitHub, and I remember standing on stage during my inaugural speech [YouTube Link] and sharing a vision that sounded almost like science fiction at the time: that one day this technology would be so simple and efficient it could replace some of the most boring tasks of scientists. Looking back years later, it gives me goosebumps to say: that dream is now a reality! (However, I don’t think experts should be fully replaced by AI, they should re-invent their role, but that is another blog-post!).
The Vision and the Virus
Despite the technical look, we knew we had something special. We published the code on GitHub, and I remember standing on stage during my inaugural speech [YouTube Link] and sharing a vision that sounded almost like science fiction at the time: that one day this technology would be so simple and efficient it could replace some of the most boring tasks of scientists. Looking back years later, it gives me goosebumps to say: that dream is now a reality! (However, I don’t think experts should be fully replaced by AI, they should re-invent their role, but that is another blog-post!)
Then, the world changed overnight.

When the COVID-19 crisis struck in early 2020, Jonathan and I looked at the situation and knew we couldn’t stick to business as usual. We cleared our entire agendas. We realized that doctors and guideline developers were suddenly drowning in an explosion of new COVID research, and they didn’t have time to learn how to write code. They needed a tool that was as easy to use as a web browser.
We went into overdrive to build a proper, user-friendly interface. Recognizing the urgency, the NWO (Dutch Research Council) awarded us a grant to fast-track the integration of the CORD-19 database. This allowed researchers to instantly search and screen the massive wave of global COVID-19 data, separating crucial science from the noise when it mattered most.
The integration of the CORD-19 database didn’t just help researchers; it caught the eye of the media. But for us, the crowning achievement was scientific validation when our work was featured on the front cover of Nature Machine Intelligence . In this paper, we didn’t just claim it worked; we proved it. We ran simulation studies that mimicked a human using the active learning pipeline versus the old-fashioned way. The results were crystal clear: the time saved with our software was enormous.
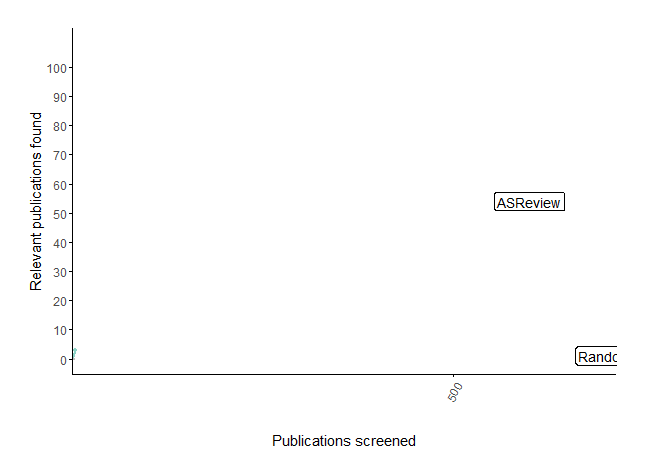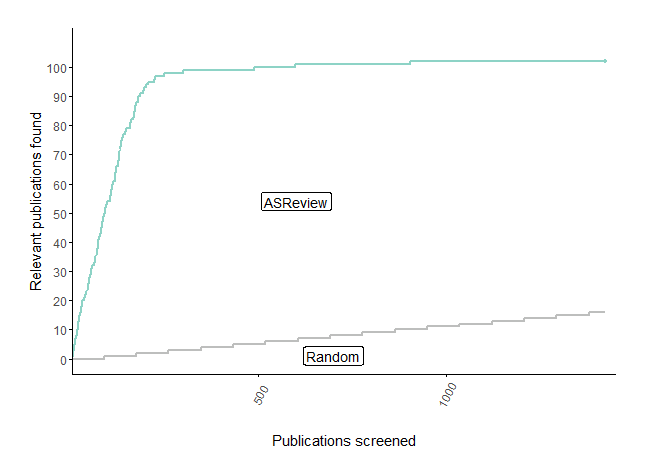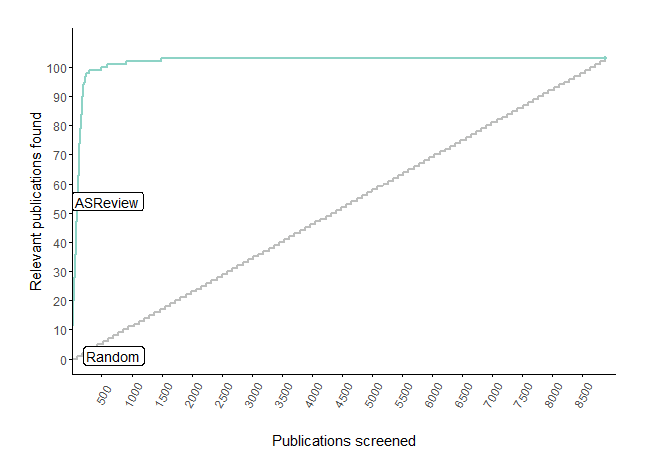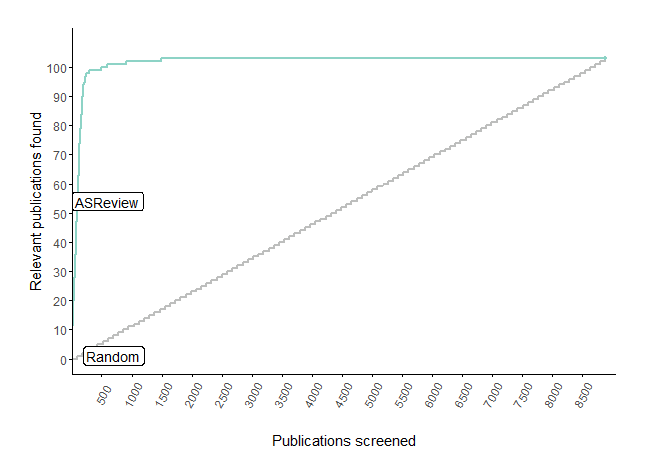
Global Adoption and Validation
The project grew from a small team into an official university AI-Lab. We secured more grants and welcomed a wave of brilliant thesis-students who were eager to help. Simultaneously, our online community exploded. Developers from around the world started pitching in: fixing bugs, writing code, and adding new features. What started in a hallway was now a global collaboration.
To test applicability in real-world clinical settings, we collaborated with external partners like the Knowledge Institute for the Federation of Medical Specialists, demonstrating that AI could maintain high recall while significantly reducing workload for medical guidelines. Crucially, these findings were subsequently corroborated by independent scientists testing its performance outside our lab and with many different types of data, providing essential third-party verification of the software’s performance and reliability.
The ASReview Universe
As the community expanded, the project outgrew its original scope as a single software tool. We restructured ASReview into a comprehensive organization on GitHub, creating a distinct ecosystem of tools. While the core interactive screening interface is now officially named ASReview LAB, it is supported by a vast ‘ASReview universe.’ This modular architecture allows for a flexible suite of add-ons, plugins, and auxiliary packages that extend functionality far beyond basic screening.
This modular approach allowed the community to expand the ecosystem with plugins for data pre-processing (see asreview-datatools) and post-processing, such as tools to calculate Inter-Rater Reliability directly from ASReview output files alongside the Insights package for advanced metrics and visualizations, and templates for seamlessly integrating models from Hugging Face.
The validation infrastructure evolved perhaps even more rapidly than the screening tool itself. This includes Makita (MAKe IT Automatic), a workflow generator for simulation studies using the command line interface of ASReview LAB. Makita can be used to effortlessly generate the framework and code for running simulation studies, testing the performance of many different models on many different datasets.
To ensure this ecosystem is accessible to everyone, from individual researchers to large institutions, we invested heavily in deployment flexibility. We containerized the entire application stack using Docker, allowing ASReview LAB to run consistently on any operating system without complex installation hurdles. For organizations handling sensitive data or requiring centralized access, we developed a robust Server Stack, including authentication and security layers. This allows research groups to host their own secure instance of ASReview, enabling collaborative screening on a private server while keeping full control over their data governance.
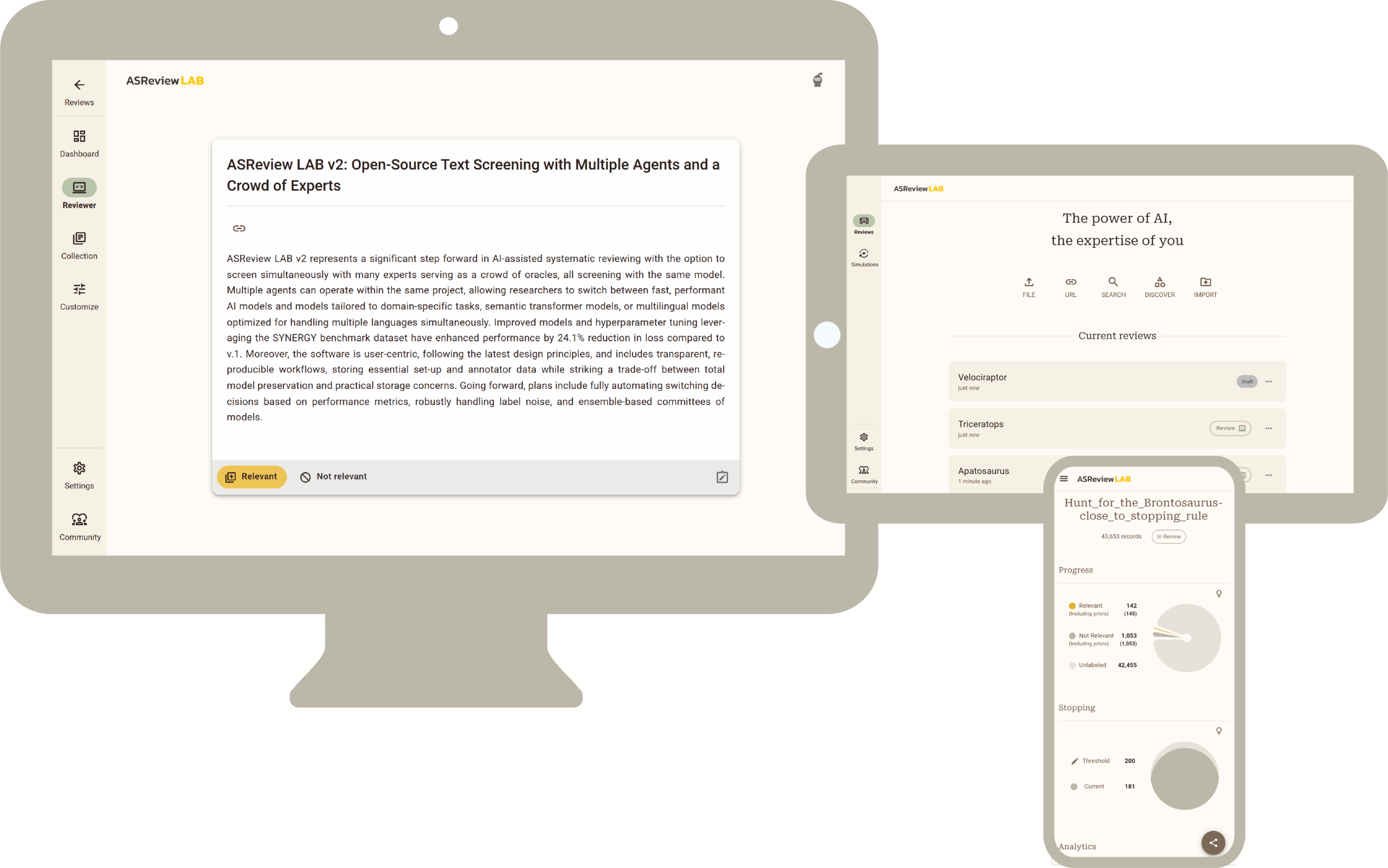
Optimization and Strategy
In parallel with these structural improvements, we conducted rigorous hyperparameter tuning to boost model performance. Early versions of ASReview relied on a limited benchmark of just five datasets. For Version 2, we scaled this up significantly, utilizing the 26 open datasets available via the SYNERGY project. Using the SYNERGY benchmark dataset, performance has improved significantly, with a 24.1% reduction in loss compared to version 1 through model improvements and hyperparameter tuning. ASReview LAB v.2 follows user-centric design principles and offers reproducible, transparent workflows. It logs key configuration and annotation data while balancing full model traceability with efficient storage.
As detailed in our Patterns paper, this large-scale optimization revealed a crucial insight: specific, lightweight model configurations could yield consistent, high-performance results across diverse domains without requiring massive computational power. Guided by these findings, we made a strategic shift. The default model in ASReview LAB is now lightweight and fast, ensuring the software remains accessible on standard laptops. For users requiring maximum power or domain-specific nuances, we developed the Dory package. This extension enables the seamless integration of fine-tuned ‘heavy’ models and a wide range of other Transformer models, but it requires additional hardware with sufficient compute power.
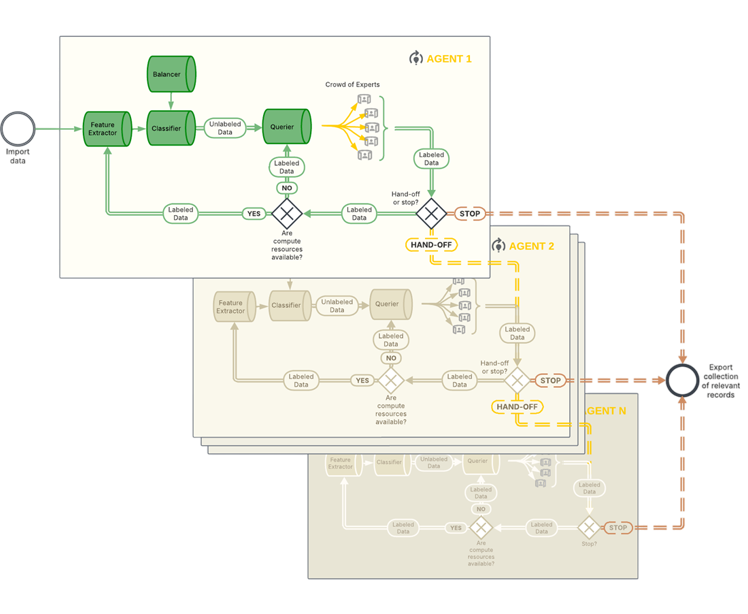
Crowd Screening and Bias Research
Thanks to the IHI grant IMPROVE, where I also met Frans Folkvord, we were able to pilot a groundbreaking new mode: Crowd-based screening. In this collaborative setup, a group of experts screens documents simultaneously, all training the same shared model in real-time. Imagine a ‘hive mind’ approach: every time one expert makes a decision, the model instantly learns and updates its recommendations for the entire group. This parallel processing allows teams to screen enormous volumes of records in a fraction of the time it would take a single reviewer, effectively combining human expertise with distributed AI efficiency .
Looking toward the future, the recently awarded VICI grant (2025-2031) marks the beginning of a new chapter in fundamental research. To support this inquiry, we are expanding the SYNERGY data repository to include 140 datasets containing over half a million records. This massive collection of labelled data will serve as a vital testbed for advanced simulation studies and the training of domain-specific hyperparameters.
Another focus of this grant is the critical interplay between AI suggestions and human bias. Our findings demonstrate that AI-generated cues, such as confidence scores or highlighting, can introduce powerful authority biases in human-AI collaborative screening. Consequently, we have made a deliberate design choice. We keep the interface as simple as possible, showing only what really matters: the text to read. By removing distractions, we ensure the human remains the true ‘Oracle,’ unbiased by the machine’s opinion (or that they are influenced by journal or author names).
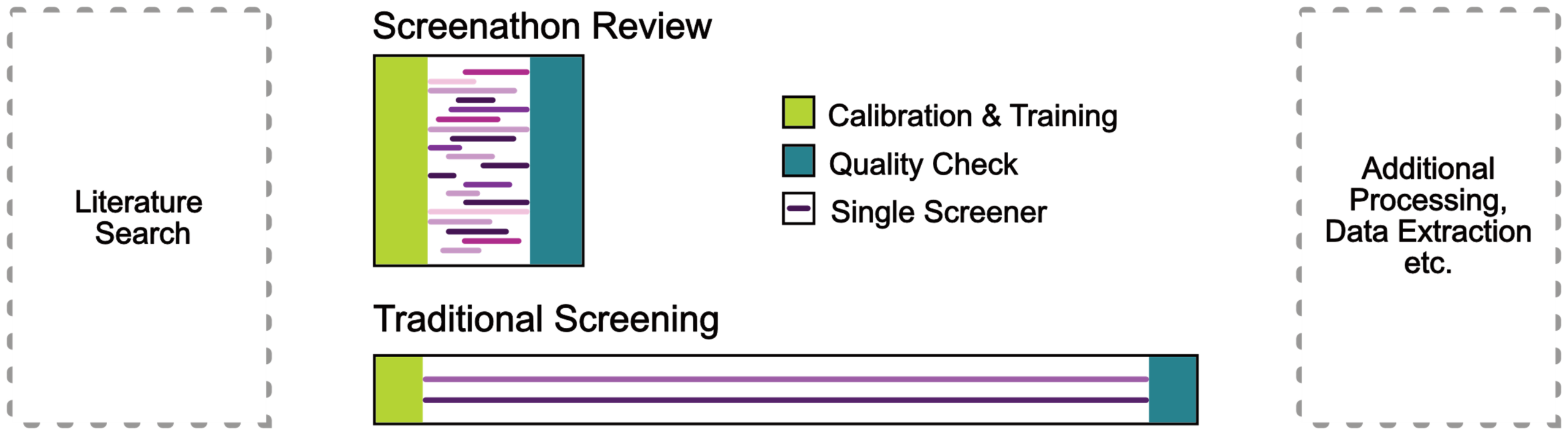
Built to Last: Our Open-Source Pledge
Beyond the cloud, the software is now a staple in full production environments. It powers not only scientific discovery but also critical societal infrastructure, including medical guidelines, dosage recommendations, and food safety standards. Furthermore, SURF has officially integrated ASReview into its Research Cloud. This makes the software freely available to all connected scientists in the Netherlands and demonstrates the ultimate level of Technology Readiness (TRL 9): Full Deployment.
Globally, ASReview LAB has become the go-to tool for a wide spectrum of evidence synthesis tasks, from standard systematic reviews and meta-analyses to Evidence Gap Maps, Living Reviews, and the creation of labeled datasets for machine learning. Its utility has transcended academia entirely, finding applications in policy analysis, investigative journalism, and educational settings.
So, anyone can download and install the software today. You can run it locally on your laptop (see installation guide), deploy it on a server via Docker (see instructions), or host your own secure instance.
This accessibility is the true power of open-source software. Thanks to the generous long-term funding from the Dutch Research Council (NWO), specifically the VICI and the NWA-ORC Decide grants, we can guarantee that ASReview will remain free, open, and actively maintained for the years to come.
We are often asked if there is a commercial strategy behind this. The answer is simple: No. Our mission is to democratize state-of-the-art evidence synthesis, not to monetize it. This tool belongs to the community, made possible by public funding and the dedication of countless volunteers.
Podcast
The Inside ELAS podcast takes you into the heart of the ASReview community. In each episode, we go beyond the changelogs to hear from the researchers, developers, students, and librarians shaping the project. Join us as we rethink how we work together in open science—discussing everything from design decisions and research questions to the diverse voices that make it all possible.
YouTube
Dive into our growing video library on ASReview-tv. Whether you are looking for technical tutorials, clear animations of active learning concepts, or insightful interviews with the community, you’ll find it all here. It’s the visual hub for mastering the ASReview ecosystem.