
Small Samples
Researchers often have difficulties collecting enough data to obtain statistical power: when target groups are small (e.g., children with severe burn injuries), hard to access (e.g., infants of drug-dependent mothers), or measuring the participants requires prohibitive costs (e.g., measuring phonological difficulties of babies). Such obstacles to collecting data usually leads to a limited data set. Researchers can overcome this through simplifying their hypotheses and statistical models. However, this strategy is undesirable since the intended research question cannot be answered in this way.
The issue of limited data can be dealt with through Bayesian statistics, if and only if background knowledge is available. With Bayesian statistics, background knowledge about the parameters in a model can be incorporated into the statistical analyses, by means of the so-called ‘prior distribution’. The integration of this prior knowledge through this distribution reduces convergence issues and the likelihood of obtaining impossible parameters, and puts less restrictions of the size of the data set. Often the background knowledge stems from systematic reviews, meta-analyses or previous studies on similar data sets.
In this project, I investigate how much background information is required to overcome the limited data issue, where to obtain the necessary background information, how to elicit this information, and how to properly report this complete process.
Ongoing
In my VIDI*-project we work on several projects related to small data. [more information will follow soon]
*The VIDI is part of the innovational research incentives scheme of The Netherlands Organization for Scientific Research. The VIDI is the second (out of three) grants to develop their own research group.
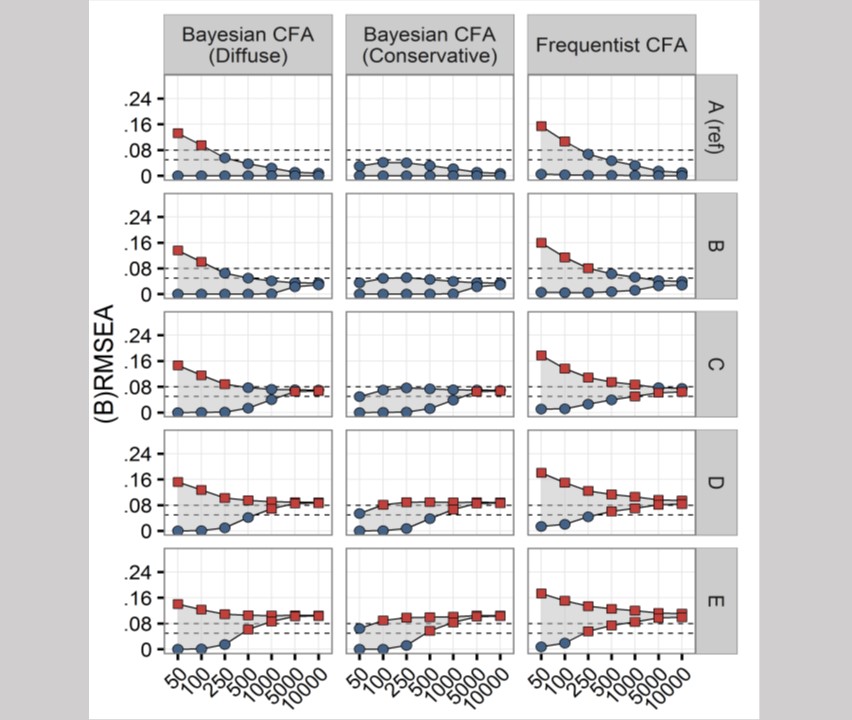
In this project, background knowledge on trauma is integrated with a statistical model that assesses individual change over time and the existence of so called ‘latent trajectories’ (Latent Growth Mixture Modeling, LGMM). Although researchers may have strong prior beliefs, the default LGMM-approach facilitates only models that fit the data. The best model is hence decided according to – among other criteria – the best fit. The issue is that the extraction of the correct number of latent trajectories is difficult for small data sets. Consequently, effects that are believed to exist in the population are not found in the data. In the current project I used Bayesian statistics to statistically improve the LGMM-model.
Completed
In my VENI*-project I showed that the analysis of small data sets in longitudinal studies can lead to power issues and often suffers from biased parameter values. These issues can be solved by using Bayesian estimation in conjunction with informative prior distributions. By means of simulation studies and several empirical examples I demonstrated the advantages and potential pitfalls of using Bayesian estimation.
*The VENI is part of the innovational research incentives scheme of The Netherlands Organisation for Scientific Research. The VENI is the first (out of three) grants to develop their own line of research.
In her current projects, Milica is focusing on optimal methods for data synthesis from non-exchangeable studies, on the consequences of specifying inaccurate priors in mediation models, and on issues that arise in applications of Bayesian mediation analysis with informative prior distributions in small samples.
Sannes PhD focuses on the use of informative priors in latent growth models with small sample sizes. She is interested in how prior knowledge can be used to compensate for small sample sizes.
Ducos PhD project with Rens focusses on providing a solution to small data problems in latent growth curve models. With few data points, it can be impossible to estimate the model of interest. Yet asking a different (simplified) question the data can answer may not be desirable.
In her PhD project, Mariëlle focuses on including prior knowledge in statistical analyses (informative Bayesian research) and confronting prior knowledge with new data.







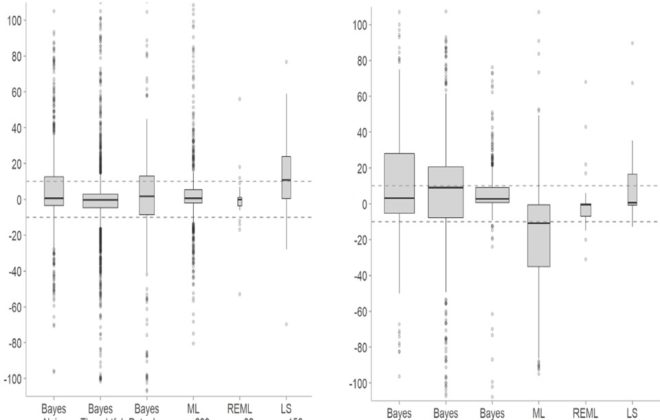








{kind=link}
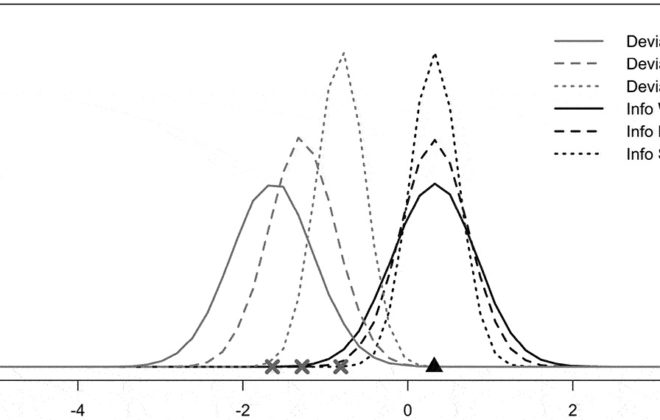
{kind=link}
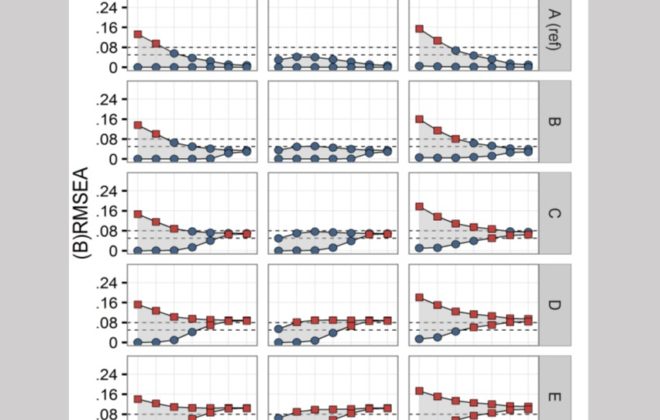
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}